
How FEE Used Umbraco to Share 70 Years of Archives
The Foundation for Economic Education turned 70 years old this year. Over the course of several decades, FEE collected a warehouse full of archives. Although the archives were eventually digitized, no one knew what to do with the scans, so they sat around for many years collecting digital dust—until now.
Here is the process we used this summer to create https://history.fee.org/
1: Scan and OCR archives
The physical documents were located in dozens of file boxes with folders. Each folder was scanned as a large PDF file, combining 30-50 individual documents. Without any metadata to describe their contents, it was impossible to make any sense of the scans.
2: Cut and tag PDF files
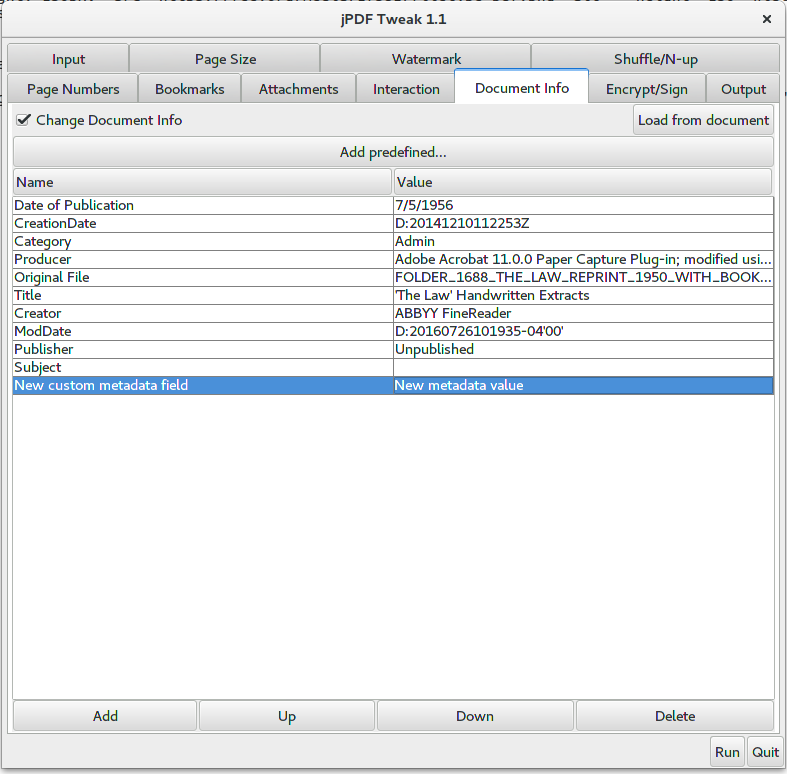
Since we wanted a separate record for each document, we had to split the large PDFs into their constituent documents. We also wanted to embed some metadata in the PDF itself both to make the files searchable and so we could use a script automate the process of populating properties for each Umbraco document node. Metadata categories included document category, publisher, authors, date of publication, comments, etc.
The tool we used to prepare the PDFs is jPDF Tweak. jPDF Tweak is a cross-platform PDF processing utility that can split PDFs, combine parts of different PDFs, embed metadata, and many other things. Any number of new metadata fields and their values can be created on the “Document Info” prior to outputting the new PDF.
Some best practices we learned:
- Use a google spreadsheet to keep track of all the individual documents being split out. This allows multiple people to work on splitting out documents without duplicating efforts. Assign a unique document number to each split PDF.
- Include the unique document number at the beginning of the filename for the new split PDF. This will come in handy later with the script that will populate the umbraco nodes. You could also include it in the metadata, although we didn’t.
The laborious process of cutting and marking up files was done by Max Hill and Max Formato.
3: Upload files to Umbraco
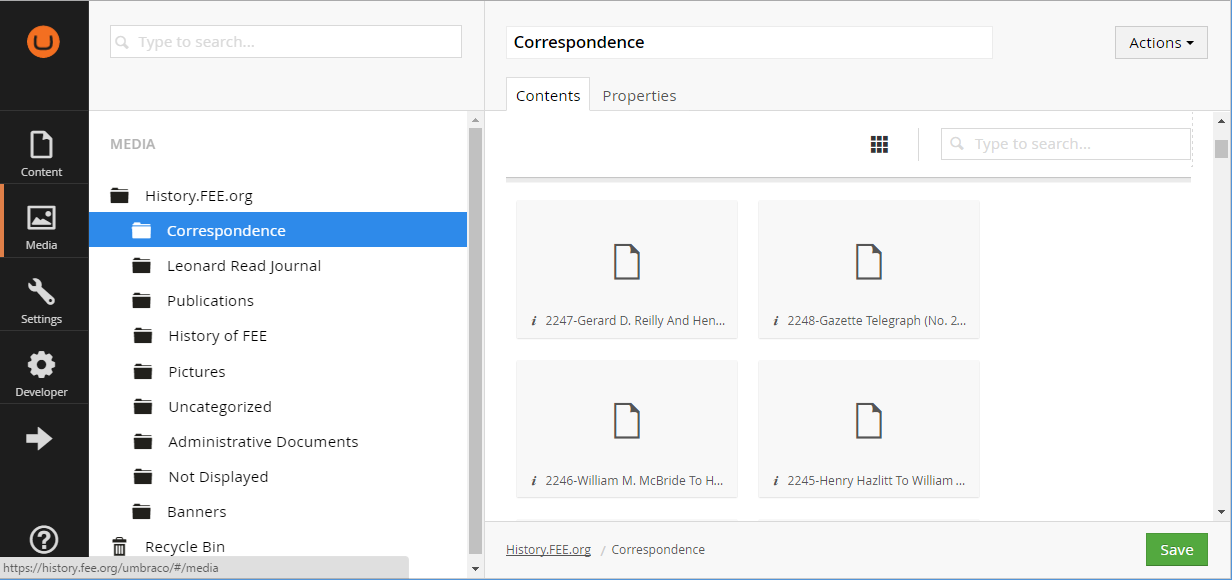
The individual PDF files were uploaded to a blank Umbraco site into high-level categories:
4: Generate documents from PDF metadata
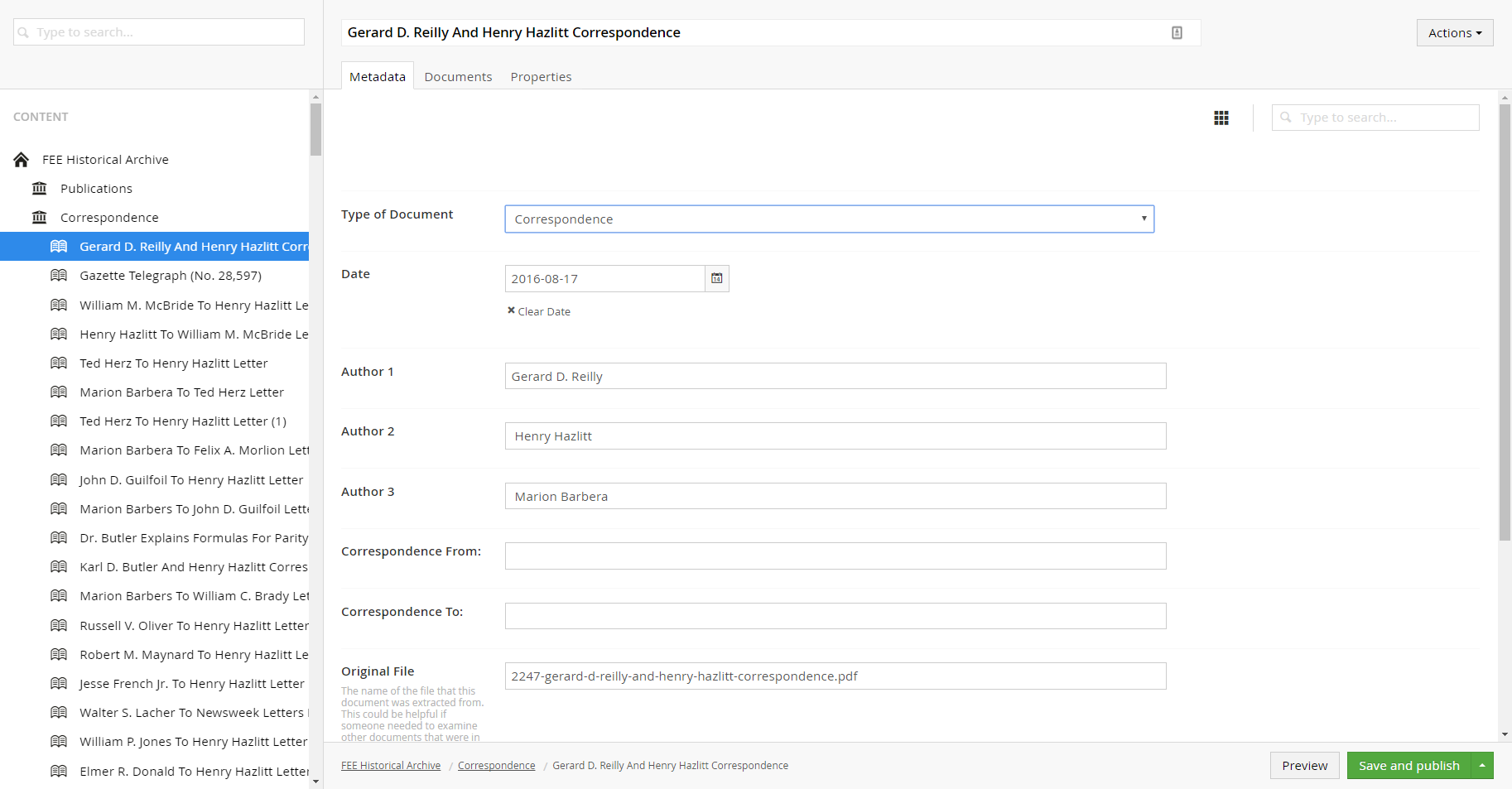
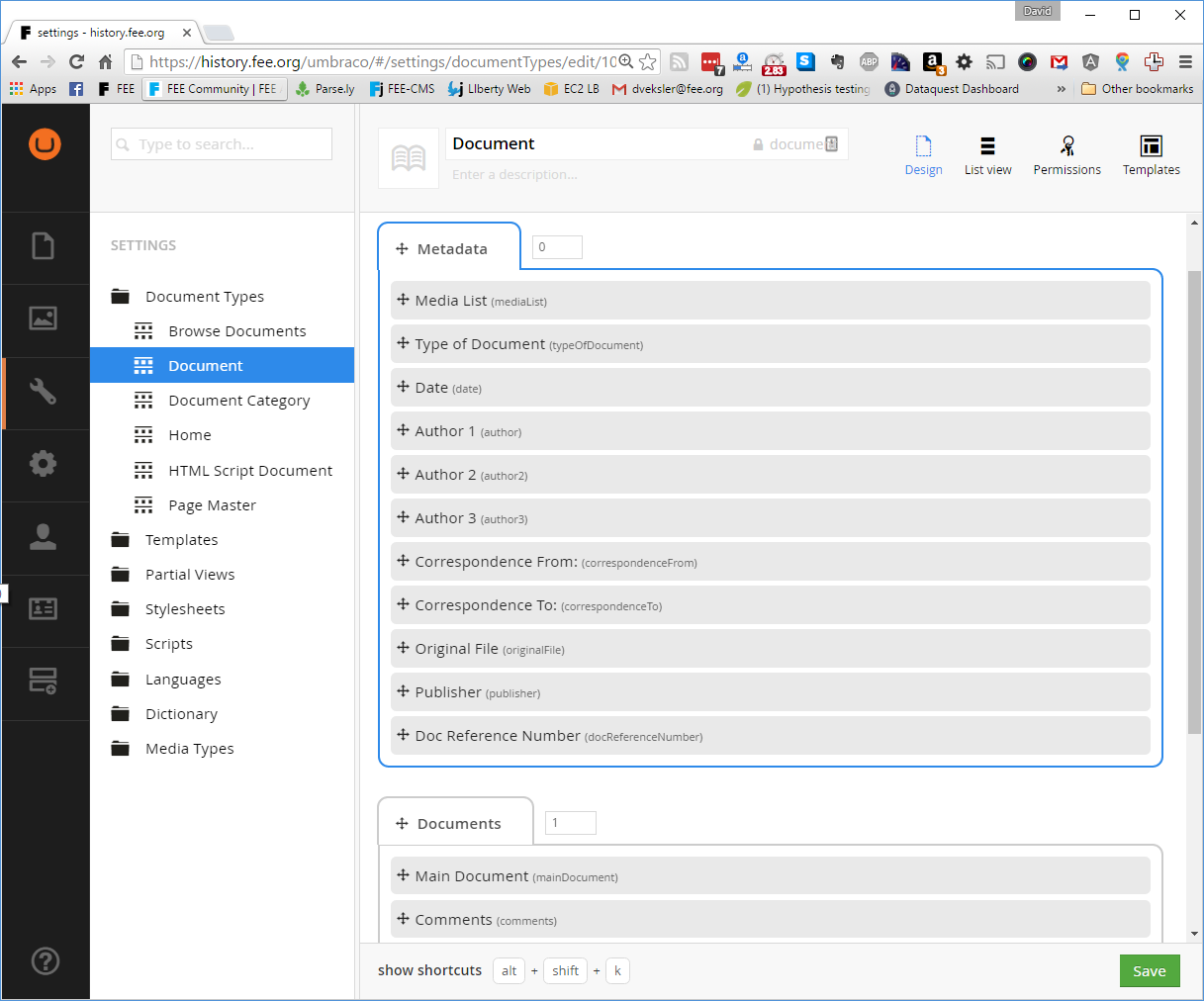
To perform the migration, we wrote a recursive script which would process folders and their contents and recreate the folder structure of the media folder as Umbraco content nodes.
First, we created Document Types in Umbraco to correspond to the custom PDF properties we created in the PDF files. We used iTextSharp to read the metadata from each PDF file and created a corresponding Umbraco document. The OCRed text of each PDF was included as a field so that search engine would have a chance to index the documents. View the source for the migration scripts.
5: Add a search engine
To make the archive searchable, we added a Google Custom Site Search Engine.
6. Create an Umbraco template
Two templates render the contents of the archives: the directory listing template and the individual document template.
7. Frontend Design (In Progress)
We built a 3-pane window using AngularJS to filter down to content. We’re still working on the polished UI—see the mockups.

Free the People publishes opinion-based articles from contributing writers. The opinions and ideas expressed do not always reflect the opinions and ideas that Free the People endorses. We believe in free speech, and in providing a platform for open dialogue. Feel free to leave a comment.


